
Excel is a spreadsheet application which is developed by Microsoft. It is an easily accessible tool to organize, analyze, and store the data in tables. It is widely used in many different applications all over the world. From Analysts to CEOs, various professionals use Excel for both quick stats and serious data crunching.
Excel Documents
An Excel spreadsheet document is called a workbook which is saved in a file with .xlsx extension. The first row of the spreadsheet is mainly reserved for the header, while the first column identifies the sampling unit. Each workbook can contain multiple sheets that are also called a worksheets. A box at a particular column and row is called a cell, and each cell can include a number or text value. The grid of cells with data forms a sheet.
The active sheet is defined as a sheet in which the user is currently viewing or last viewed before closing Excel.
Reading from an Excel file
First, you need to write a command to install the xlrd module.
pip install xlrd
Creating a Workbook
A workbook contains all the data in the excel file. You can create a new workbook from scratch, or you can easily create a workbook from the excel file that already exists.
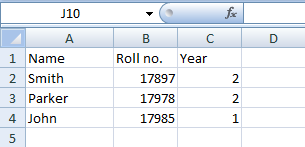
Input File
We have taken the snapshot of the workbook.
Code
# Import the xlrd module
import xlrd
# Define the location of the file
loc = ("path of file")
# To open the Workbook
wb = xlrd.open_workbook(loc)
sheet = wb.sheet_by_index(0)
# For row 0 and column 0
sheet.cell_value(0, 0)
Explanation: In the above example, firstly, we have imported the xlrd module and defined the location of the file. Then we have opened the workbook from the excel file that already exists.
Reading from the Pandas
Pandas is defined as an open-source library which is built on the top of the NumPy library. It provides fast analysis, data cleaning, and preparation of the data for the user and supports both xls and xlsx extensions from the URL.
It is a python package which provides a beneficial data structure called a data frame.
Example
import pandas as pd
# Read the file
data = pd.read_csv(".csv", low_memory=False)
# Output the number of rows
print("Total rows: {0}".format(len(data)))
# See which headers are available
print(list(data))
Reading from the openpyxl
First, we need to install an openpyxl module using pip from the command line.
pip install openpyxl
After that, we need to import the module.
We can also read data from the existing spreadsheet using openpyxl. It also allows the user to perform calculations and add content that was not part of the original dataset.
Example
import openpyxl
my_wb = openpyxl.Workbook()
my_sheet = my_wb.active
my_sheet_title = my_sheet.title
print("My sheet title: " + my_sheet_title)
Output:
My sheet title: Sheet
Leave a Reply